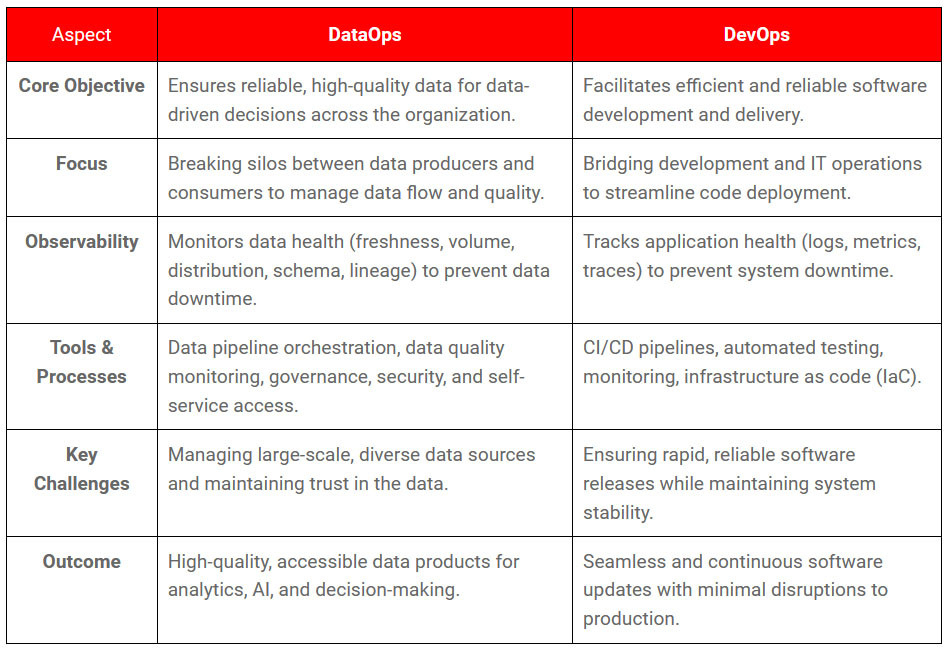
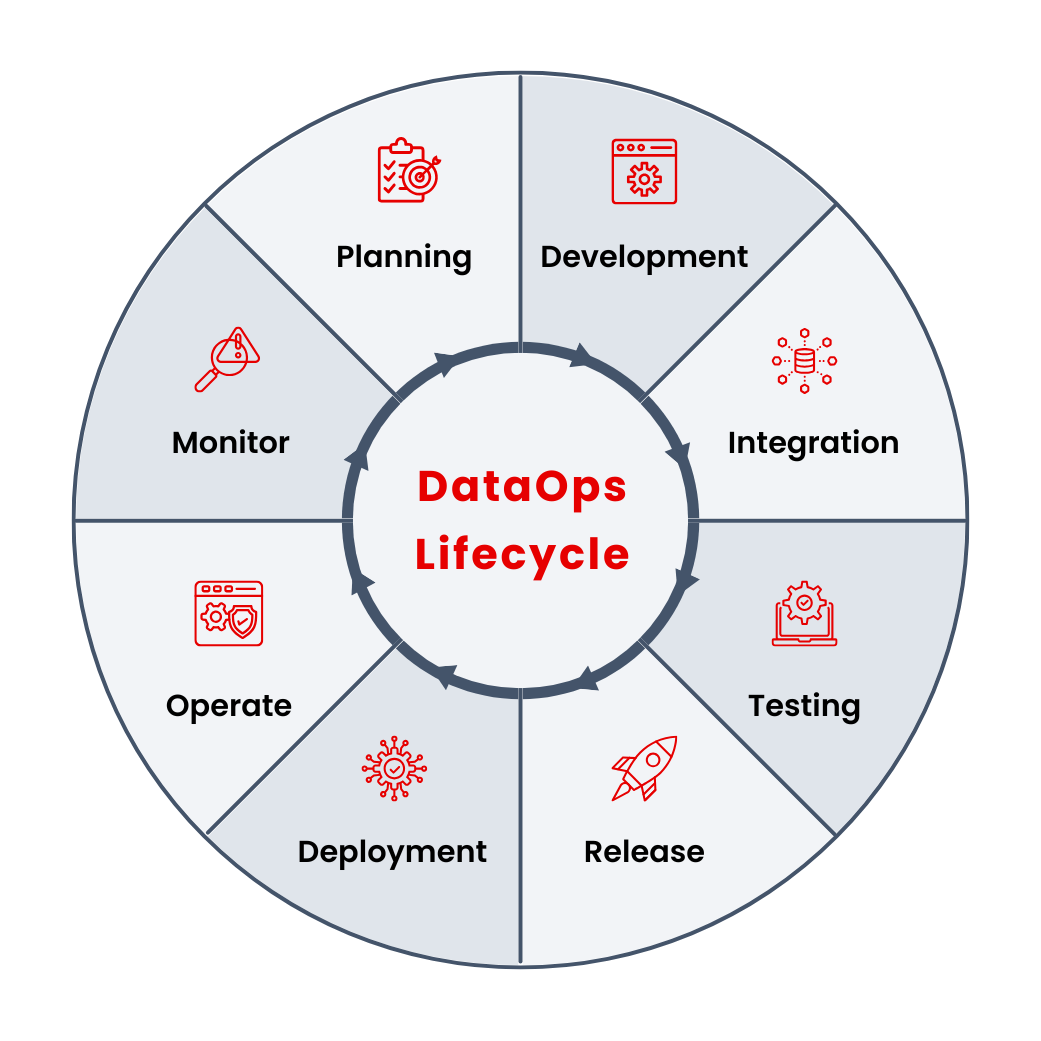
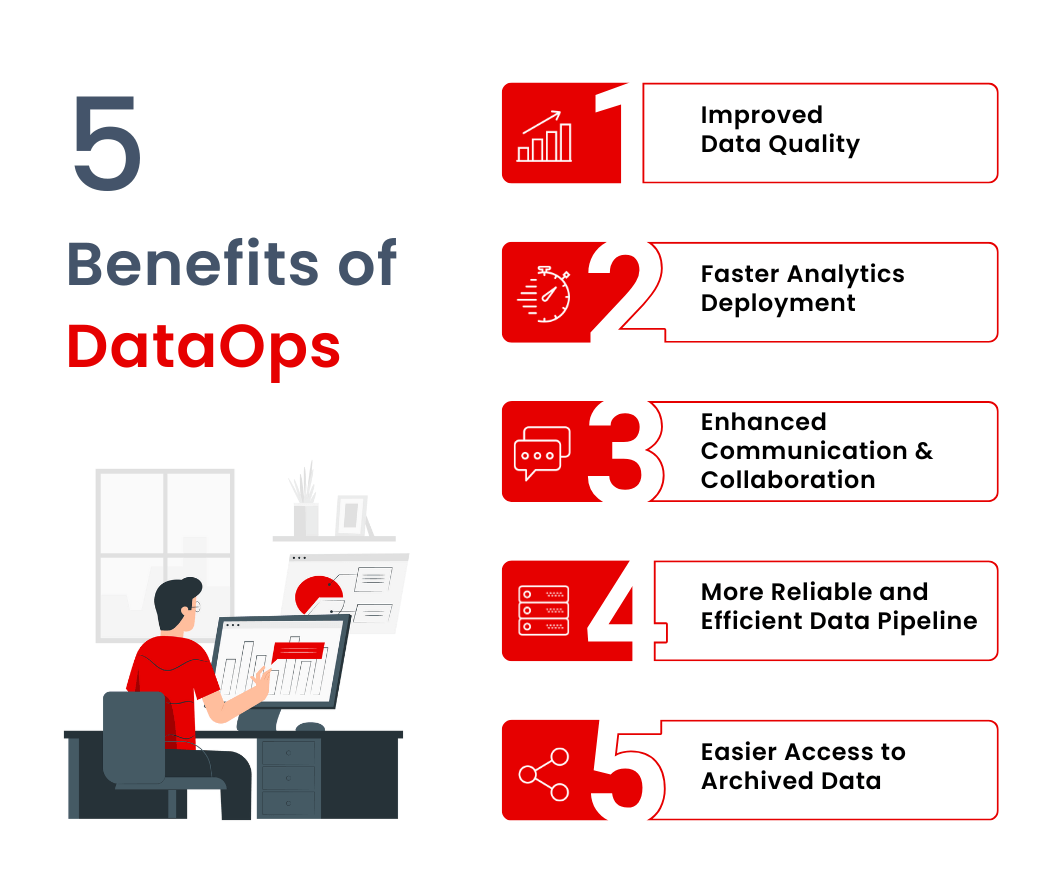
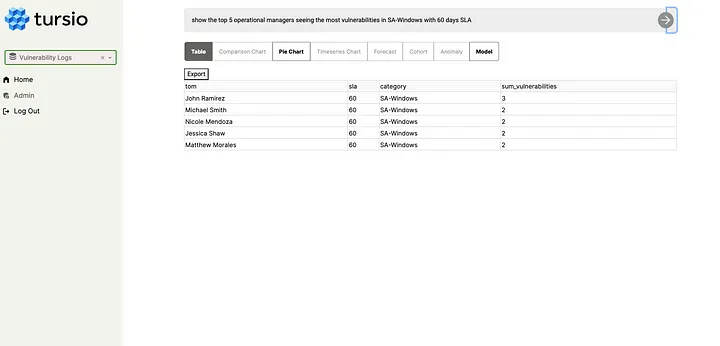
Holistic AI OSL provides the most comprehensive library for eliminating bias and improving explainability in AI systems available today
Oct. 22, 2024 – San Jose – (Business Wire) – Holistic AI, the leading AI governance platform for the enterprise, today announced the launch of Holistic AI OSL, an optimized open-source library designed to help developers build fair and responsible AI systems. AI architects and developers can now access the library, which provides advanced tools for eliminating bias and improving explainability. Holistic AI OSL empowers teams to create more transparent and trustworthy AI applications from the ground up, fostering a safer environment of innovation and experimentation to benefit society. For more information, visit the Holistic AI blog or download the library for Python, which is available today free of charge without any licensing requirements.
Organizations increasingly rely on AI systems in critical areas such as recruitment and onboarding, healthcare, loan approval and credit scoring, where fairness is paramount. It is essential to ensure that algorithms do not inadvertently discriminate, ensuring equal treatment for demographic groups and individuals. While AI has made significant advances in prediction accuracy, recent studies indicate that 65% of AI researchers and developers still identify bias as a major issue.
Holistic AI OSL tackles this challenge by providing tools that address the five key technical risks associated with AI systems, ensuring greater accountability. Specifically, OSL offers:
- Bias Mitigation: Introduces over 35 bias metrics across five machine learning tasks and provides 30 strategies to help developers eliminate bias in their systems.
- Explainability: Defines the system’s behavior by revealing how models make decisions and predictions, fostering transparency and building trust.
- Robustness: Ensures models perform consistently, even when faced with challenges like adversarial attacks or variations to input data.
- Security: Provides safeguards for user privacy through anonymization and defends against risks like attribute inference attacks, enhancing overall security.
- Efficacy: Ensures models are not only accurate but maintain fairness, robustness, and security under various conditions, balancing these factors through detailed testing in real-world scenarios.
“Our new library equips organizations with tools for all AI risks, including explainability, robustness, and bias. It supports measurement, reporting, and mitigation at every stage of the AI lifecycle, offering one of the most advanced solutions for improving quality in AI applications today,”
said Adriano Koshiyama, Co-CEO of Holistic AI.
“Our goal is to help AI realize its full potential. Whether through this open-source library or our comprehensive AI governance platform, we are committed to empowering businesses to accelerate AI innovation across their enterprise—enabling them to complete more projects successfully without facing risks, compliance issues, or bias, all while tracking against the expected ROI.”
As one of the top global insurers operating in almost 40 countries across five continents and serving over 30 million customers worldwide, MAPFRE is leveraging AI as part of its innovation strategy around continuous improvement of its customer experiences, processes, and operations. Holistic AI OSL, as well as the full Holistic AI Governance Platform, are a part of MAPFRE’s technology line up.
“What sets this library apart is its depth—it’s not just about identifying AI risks but actively addressing them with proven, industry-ready mitigation techniques, making it an essential part of any ethical AI development toolkit,”
said César Ortega, Expert Data Scientist at MAPFRE.
About Holistic AI
Founded in 2020, Holistic AI’s mission is to empower enterprises to adopt and scale AI with confidence. Our purpose-built AI governance platform helps companies accelerate AI transformation across the organization – transparently, responsibly, and with ROI accountability for the C-Suite. With Holistic AI, businesses can increase visibility and control of AI projects, eliminate communication bottlenecks across teams, and significantly reduce AI risk at enterprise scale. Holistic AI is part of Microsoft’s Founders’ Hub, Pegasus Program, and Nvidia’s Inception program. Holistic AI founders are active members of the, experts on the UN AI Advisory Body, members of OECD’s Network of Experts on AI, advisors on the EU AI Act, and collaborators to the Alan Turin Institute.
For more information, see NIST AI Safety Institute, experts on the UN AI Advisory Body, members of OECD’s Network of Experts on AI, advisors on the EU AI Act, and collaborators to the Alan Turin Institute. For more information, see www.holisticai.com.