
What is DataOps
Data workflows today have grown increasingly intricate, diverse, and interconnected. Leaders in data and analytics (D&A) are looking for tools that streamline operations and minimize the reliance on custom solutions and manual steps in managing data pipelines.
DataOps is a framework that brings together data engineering and data science teams to address an organization’s data requirements. It adopts an automation-driven approach to the development and scaling of data products. This approach also streamlines the work of data engineering teams, enabling them to provide other stakeholders with dependable data for informed decision-making.
Initially pioneered by data-driven companies who used CI/CD principles and even developed open-source tools to improve data teams—DataOps has steadily gained traction. Today, data teams of all sizes increasingly rely on DataOps as a framework for quickly deploying data pipelines while ensuring the data remains reliable and readily accessible.
Gartner defines DataOps as —
A collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization.
Why DataOps is Important
Manual data management tasks can be both time-consuming and inefficient, especially as businesses evolve and demand greater flexibility. A streamlined approach to data management, from collection through to delivery, allows organizations to adapt quickly while handling growing data volumes and building data products.
DataOps tackles these challenges by bridging the gap between data producers (upstream) and consumers (downstream). By integrating data across departments, DataOps promotes collaboration, giving teams the ability to access and analyze data to meet their unique needs. This approach improves data speed, reliability, quality, and governance, leading to more insightful and timely analysis.
In a DataOps model, cross-functional teams—including data scientists, engineers, analysts, IT, and business stakeholders—work together to achieve business objectives.
DataOps vs DevOps: Is There a Difference?
Although DevOps and DataOps sound similar, they serve distinct functions within organizations. While both emphasize collaboration and automation, their focus areas are different: DevOps is centered around optimizing software development and deployment, whereas DataOps focuses on ensuring data quality and accessibility throughout its lifecycle.
The DataOps Framework
The DataOps framework joins together different methodologies and practices to improve data management and analytics workflows within organizations. It consists of five key components:
1. Data Orchestration
Data orchestration automates the arrangement and management of data processes, ensuring seamless collection, processing, and delivery across systems. Key elements include:
- Workflow automation: Automates scheduling and execution of data tasks to enhance efficiency.
- Data integration: Combines data from diverse sources into a unified view for consistency and accessibility.
- Error handling: Detects and resolves errors during data processing to maintain integrity.
- Scalability: Adapts to increasing data volumes and complexity without compromising performance.
2. Data Governance
Data governance establishes policies and standards that guarantee the accuracy, quality, and security of data, facilitating effective management of structured data assets. Key elements include:
- Data quality management: Ensures data is accurate, complete, and reliable.
- Data security: Protects data from unauthorized access and breaches through various measures.
- Data lineage: Tracks the origin and transformation of data for transparency.
- Compliance: Ensures adherence to regulatory requirements and industry standards, such as GDPR and HIPAA.
3. Continuous Integration and Continuous Deployment (CI/CD)
The CI/CD (Continuous Integration/Continuous Deployment) practices automates testing, integration, and deployment of data applications, enhancing responsiveness. Key elements include:
- Continuous integration: Merges code changes into a shared repository with automated testing for early issue detection.
- Continuous deployment: Automates deployment of tested code to production environments.
- Automated testing: Includes various tests to ensure the correctness of data applications.
4. Data Observability
Data observability involves ongoing monitoring and analysis of data systems to proactively detect and address issues, delivering visibility into data workflows. Key elements include:
- Monitoring: Tracks the health and performance of data pipelines and applications.
- Alerting: Notifies teams of anomalies or performance issues in real time.
- Metrics and dashboards: Detects and resolves errors during data processing to maintain integrity.
- Scalability: Provides visual insights into key performance indicators (KPIs).
5. Automation
Automation minimizes manual intervention by utilizing tools and scripts to perform repetitive tasks, enhancing efficiency and accuracy in data processing. Key elements include:
- Task automation: Automates routine tasks like ETL and reporting.
- Workflow automation: Streamlines complex workflows using dependencies and scheduling.
- Self-service: Enables users to access and analyze data independently through user-friendly interfaces.
How Does DataOps Works
DataOps primarily consists of the following four processes:
- Data Integration: This process aims to create a cohesive view of fragmented and distributed organizational data through seamless, automated, and scalable data pipelines. The objective is to efficiently locate and integrate the appropriate data without sacrificing context or accuracy.
- Data Management: This implies automating and optimizing data processes and workflows from creation to distribution, throughout the entire data lifecycle. Agility and responsiveness are essential for effective DataOps.
- Data Analytics Development: This process facilitates rapid and scalable data insights by utilizing optimal, reusable analytics models, user-friendly data visualizations, and continuous innovation to enhance data models over time.
- Data Delivery: The goal here is to ensure that all business users can access data when it is most needed. This extends beyond just efficient storage; it emphasizes timely data access with democratized self-service options for users.
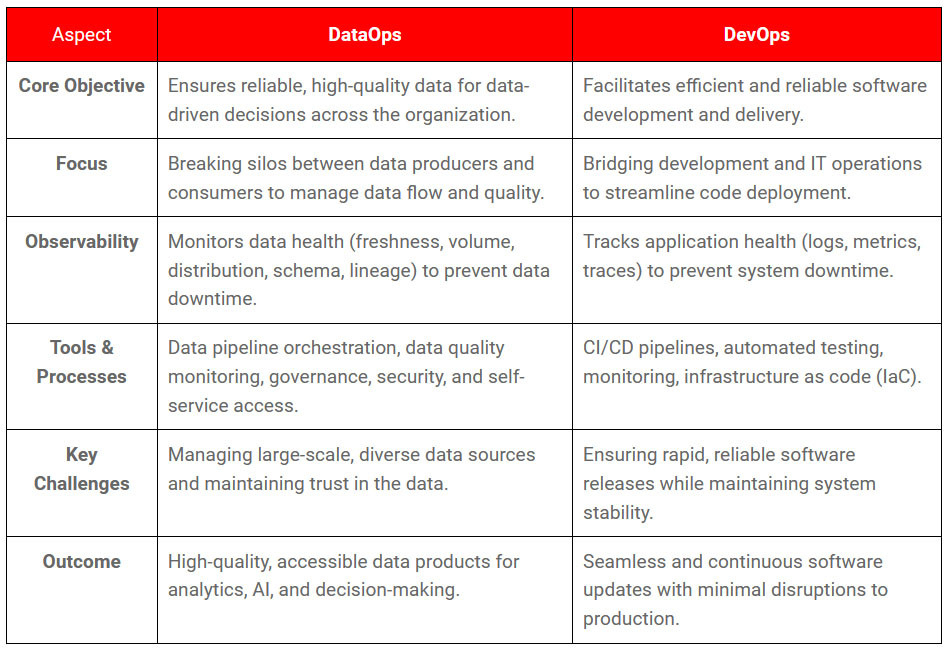
In practice, the key phases in a DataOps lifecycle include:
- Planning: Collaborating with teams to set KPIs and SLAs for data quality and availability.
- Development: Building data products and machine learning models.
- Integration: Incorporating code or data products into existing systems.
- Testing: Verifying data against business logic and operational thresholds.
- Release: Deploying data into a test environment.
- Deployment: Merging data into production.
- Operate: Running data in applications to fuel ML models.
- Monitor: Continuously checking for anomalies in data.
This iterative cycle promotes collaboration, enabling data teams to effectively identify and prevent data quality issues by applying DevOps principles to data pipelines.
Who Owns DataOps
DataOps teams usually incorporate temporary stakeholders throughout the sprint process. However, each DataOps team relies on a core group of permanent data professionals, which typically includes:
- The Executive (CDO, CTO, etc.): This leader guides the team in delivering business-ready data for consumers and leadership. They ensure the security, quality, governance, and lifecycle management of all data products.
- The Data Steward: Responsible for establishing a data governance framework within the organization, the data steward manages data ingestion, storage, processing, and transmission. This framework serves as the foundation of the DataOps initiative.
- The Data Quality Analyst: Focused on enhancing the quality and reliability of data, the data quality analyst ensures that higher data quality leads to improved results and decision-making for consumers.
- The Data Engineer: The data engineer constructs, deploys, and maintains the organization’s data infrastructure, which includes all data pipelines and SQL transformations. This infrastructure is crucial for ingesting, transforming, and delivering data from source systems to the appropriate stakeholders.
- The Data/BI Analyst: This role involves manipulating, modeling, and visualizing data for consumers. The data/BI analyst interprets data to help stakeholders make informed strategic business decisions.
- The Data Scientist: Tasked with producing advanced analytics and predictive insights, the data scientist enables stakeholders to enhance their decision-making processes through enriched insights.
Benefits of DataOps
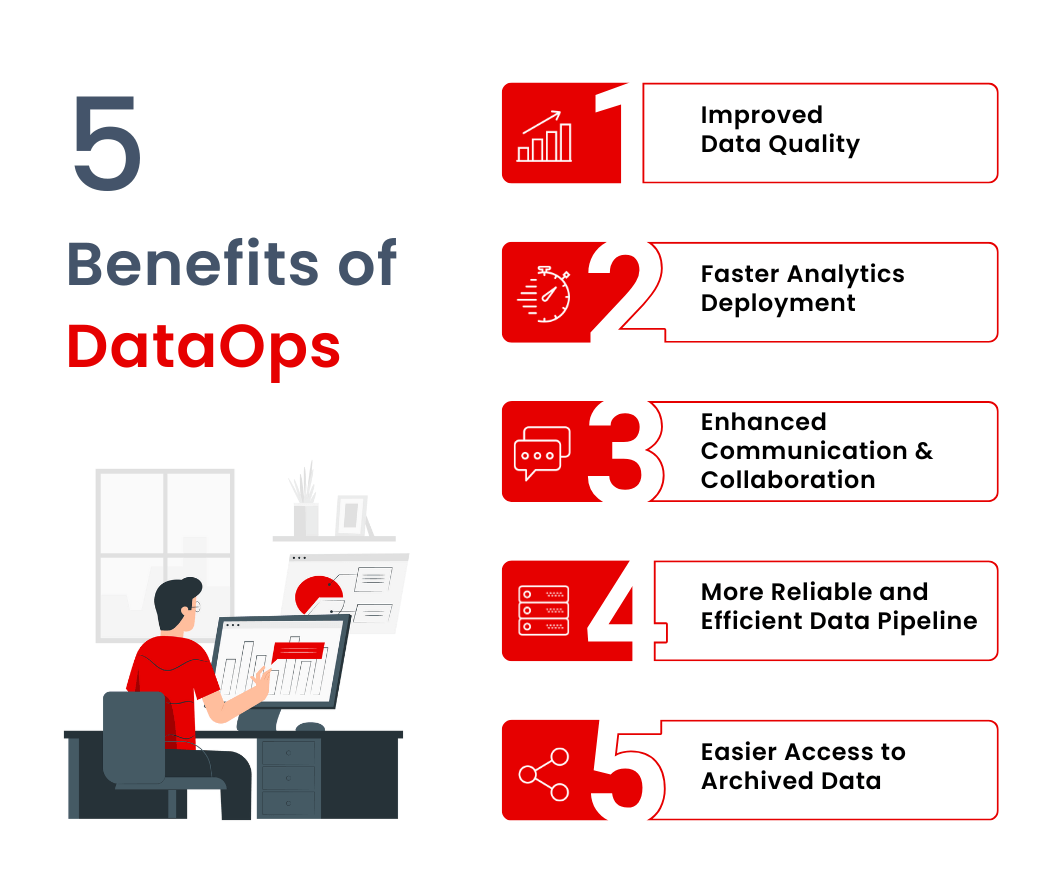
Adopting a DataOps solution offers numerous benefits:
1. Improved Data Quality
DataOps enhances data quality by automating traditionally manual and error-prone tasks like cleansing, transformation, and enrichment. This is crucial in industries where accurate data is vital for decision-making. By providing visibility throughout the data lifecycle, DataOps helps identify issues early, enabling organizations to make faster, more confident decisions.
2. Faster Analytics Deployment
Successful DataOps implementation can significantly decrease the frequency of late data analytics product deliveries. DataOps accelerates analytics deployment by automating provisioning, configuration, and deployment tasks, which reduces the need for manual coding. This allows data engineers and analysts to quickly iterate solutions, resulting in faster application rollouts and a competitive edge.
3. Enhanced Communication and Collaboration
DataOps fosters better communication and collaboration among teams by centralizing data access. This facilitates cross-team collaboration and improves the efficiency of releasing new analytics developments. By automating data-related tasks, teams can focus on higher-level activities, such as innovation and collaboration, leading to better utilization of data resources.
4. More Reliable and Efficient Data Pipeline
DataOps creates a more robust and faster data pipeline by automating data ingestion, warehousing, and processing tasks, which reduces human error. It improves pipeline efficiency by providing tools for management and monitoring, allowing engineers to proactively address issues.
5. Easier Access to Archived Data
DataOps simplifies access to archived data through a centralized repository, making it easy to query data compliantly and automating the archiving process to enhance efficiency and reduce costs. DataOps also promotes data democratization by making vetted, governed data accessible to a broader range of users, optimizing operations and improving customer experiences.
Best Practices for DataOps
Data and analytics (D&A) leaders should adopt DataOps practices to overcome the technical and organizational barriers that slow down data delivery across their organizations. As businesses evolve rapidly, there is an increasing need for reliable data among various consumer personas, such as data scientists and business leaders. This has heightened the demand for trusted, decision-quality data.
DataOps begins with cleaning raw data and establishing a technology infrastructure to make it accessible. Once implemented, collaboration between business and data teams becomes essential. DataOps fosters open communication and encourages agile methodologies by breaking down data processes into smaller, manageable tasks. Automation streamlines data pipelines, minimizing human error.
Building a data-driven culture is also vital. Investing in data literacy empowers users to leverage data effectively, creating a continuous feedback loop that enhances data quality and prioritizes infrastructure improvements. Treating data as a product requires stakeholder involvement to align on KPIs and develop service level agreements (SLAs) early in the process. This ensures focus on what constitutes good data quality within the organization.
To successfully implement DataOps, keep the following best practices in mind:
- Define data standards early: Establish clear semantic rules for data and metadata.
- Assemble a diverse team: Build a team with various technical skills.
- Automate for efficiency: Use data science and BI tools to automate processing.
- Break silos: Encourage communication and utilize integration tools.
- Design for scalability: Create a data pipeline that adapts to growing data volumes.
- Build in validation: Continuously validate data quality through feedback loops.
- Experiment safely: Use disposable environments for safe testing.
- Embrace continuous improvement: Focus on ongoing efficiency enhancements.
- Measure progress: Establish benchmarks and track performance throughout the data lifecycle.
By treating data like a product, organizations can ensure accurate, reliable insights to drive decision-making.
Conclusion
By automating tasks, enhancing communication and collaboration, establishing more reliable and efficient data pipelines, and facilitating easier access to archived data, DataOps can significantly improve an organization’s overall performance.
However, it’s important to note that DataOps is not a one-size-fits-all solution; it won’t automatically resolve all data-related challenges within an organization.
Nevertheless, when implemented effectively, a DataOps solution can enhance your organization’s performance and help sustain its competitive advantage.

